Amazon Athena should be your preferred choice when running ad-hoc SQL queries on data that is stored in Amazon S3. It doesn’t require you to set up or manage any infrastructure resources, and you don’t need to move any data. It supports structured, unstructured, and semi-structured data. With Athena, you are defining a “schema on read” -- you basically just log in, create a table and you are good to go.
Amazon Redshift is targeted for modern data analytics on large, peta-byte scale, sets of structured data. Here, you need to have a predefined “schema on write”. Unlike serverless Athena, Redshift requires you to create a cluster (compute and storage resources), ingest the data and build tables before you can start to query, but caters to performance and scale. So for any highly-relational data with a transactional nature (data gets updated), workloads which involve complex joins, and latency requirements to be sub-second, Redshift is the right choice.
Athena and Redshift are optimized for read-heavy analytics workloads - and therefore not replacements for write-heavy, relational databases such as Amazon Relational Database System (RDS) and Aurora. At a high level, use Athena for exploratory analytics and operational debugging; use Redshift for business-critical reports and dashboards.
In this article, we will explore how to implement distributed tracing using Jaeger and visualize the traces using Jaeger UI.
Introduction
Jaeger is an open-source distributed tracing mechanism that helps to trace requests in distributed systems. It is based on opentracing specification and is a part of the Cloud Native Computing Foundation (CNCF).
Let’s create an application from https://start.spring.io with only a single dependency “Spring Web”.
Once you generate and download the code, we will add the following Jaeger dependency to the pom file which will help to generate and propagate the traces between the services.
public Controller(RestTemplate restTemplate) { this.restTemplate = restTemplate; }
@GetMapping("/path1") public ResponseEntity path1() {
logger.info("Incoming request at {} for request /path1 ", applicationName); String response = restTemplate.getForObject("http://localhost:8090/service/path2", String.class); return ResponseEntity.ok("response from /path1 + " + response); }
@GetMapping("/path2") public ResponseEntity path2() { logger.info("Incoming request at {} at /path2", applicationName); return ResponseEntity.ok("response from /path2 "); } }
Here, we have two endpoints /path1 and /path2 . The idea here is to use two instances of the same application such that/path1 calls /path2 of another service at a fixed port 8090.
For the spans to get connected to the same trace id, We need to create a RestTemplate bean to allow Jaeger to include an interceptor. This then helps to add traces to the outgoing request which will help to trace the entire request.
@Bean public RestTemplate restTemplate(RestTemplateBuilder builder) { return builder.build(); }
With this done, Let’s start a Jaeger Server locally using docker. For this, I have created a docker-compose file with the port mappings.
We can communicate with Jaeger using either via UDP or TCP. After starting the docker image using docker-compose up , we can access the UI using the URL http://localhost:16686/
Now, let's add some properties to allow the application to send the traces to the Jaeger server. We will communicate via TCP, so make sure that we send the traces to the other TCP port. i.e 14268
Once the application starts, call “Service 1” at /path1 as follows
curl -i http://localhost:8080/service/path1
Let’s look at the logs of “Service 1”.
INFO 69938 --- [nio-8080-exec-1] i.j.internal.reporters.LoggingReporter : Span reported: ed70bbaa2bd5b42f:c7c94163fc95fc1e:ed70bbaa2bd5b42f:1 - GET
The tracing is of the format [Root Span Id, Current Span Id, Parent Span Id]. In this case, since “Service 1” is the originating service, the parent span Id “ed70bbaa2bd5b42f” is also the root span id.
Here we see that the middle value is the current span id and the parent span id (ie. the third value “c7c94163fc95fc1e”) is the span id of “Service 1”.
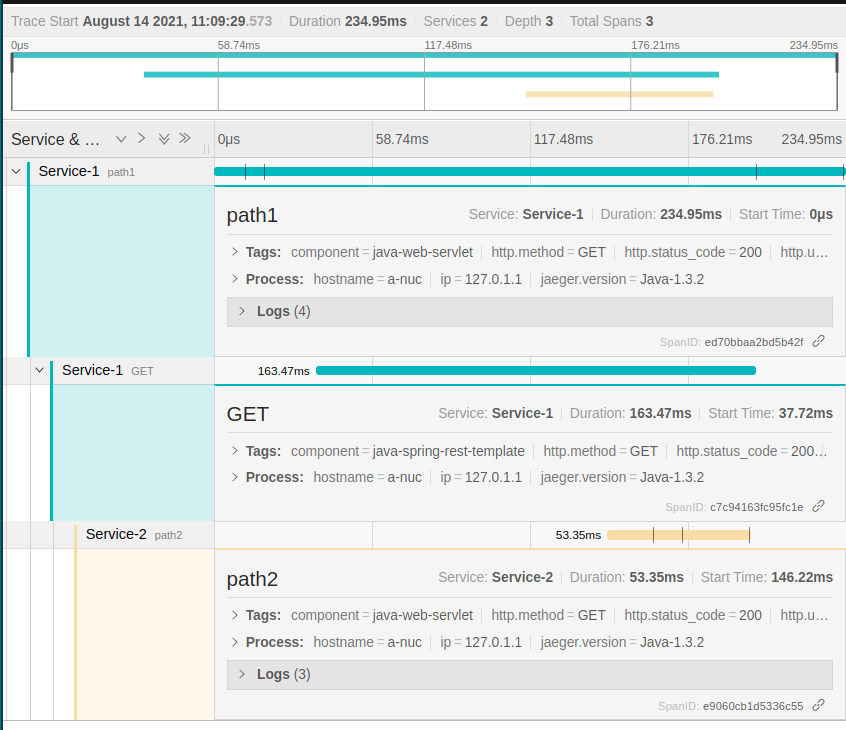
Now, If you open the UI you will see the following.
When we dig deeper, we see more details on each of the spans.
Here, the root span id “ed70bbaa2bd5b42f” spans across the entire request. The other two span ids refer to the individual services.
Conclusion
Today we explored how we can integrate Jaeger which is based on OpenTracing with a spring boot application. You can always read more in-depth about the specification of OpenTracing here. Also, the library documentation for using spring cloud Jaeger is here.
You can read about Distributed tracing using Zipkin my previous article here.
I keep exploring and learning new things. If you want to know the latest trends and improve your software development skills, then subscribe to my newsletter on https://refactorfirst.com and also follow me on Twitter.
Enjoy!!
Distributed Tracing with Spring Cloud Sleuth And Zipkin
In this article, we would learn how we can implement distributed tracing and understand the key concepts of distributed tracing.
Introduction
In the case of a single giant application that does everything which we usually refer to as a monolith, tracing the incoming request within the application was easy. We could follow the logs and then figure out how the request was being handled. There was nothing else we would have to look at but the application logs themselves.
Over time, monoliths become difficult to scale, to serve a large number of requests as well as delivering new features to the customer with the growing size of the codebase. This leads to breaking down the monolith into microservice which helps in scaling individual components and also helps to deliver faster.
But not all that shines is gold, right? It’s the same thing with microservices. We split the entire monolith system into microservices and every request that was processed by a set of local function calls is now replaced by calling a set of distributed services. With this, we lose things like tracing a request that was easily done in a monolith. Now to trace each request we would have to look at the logs of each service and it becomes difficult to correlate.
So in the case of distributed systems, the concept of distributed tracing helps with tracing a request.
What is Distributed Tracing?
Distributed tracing is a mechanism with which we can trace a particular request throughout a distributed system. It allows us to track how a request progresses from one system to another thereby completing the user’s request.
Key concepts of Distributed Tracing.
Distributed tracing consists of two main concepts
Trace Id
Span Id
Trace Id is used to trace an incoming request and track it across all the composing services to satisfy a request.
Span Id is more of spans in between service calls to track each request that is received and to the response that is sent out.
let’s have a look at the diagram.
The incoming request doesn’t have any Trace id, the first service intercepting the call generates the trace id “ID1” and its span id “A”. The span id “B” covers the time from when the client at server 1 sent out the request, then server 2 receiving it, processing it, and sending out the response.
With the concepts understood, let’s now do this practically and understand more inside details.
Spring Boot Example With Spring Cloud Sleuth
Let’s create an application with spring cloud sleuth integrated. To start, let’s go to https://start.spring.io/ and create an application with the dependencies “Spring Web” and “Spring Cloud Sleuth”.
Now let’s create a simple controller with two request mapping.
publicclassController{privatestaticfinalLoggerlogger=LoggerFactory.getLogger(Controller.class);privateRestTemplaterestTemplate;@Value("${spring.application.name}")privateStringapplicationName;publicController(RestTemplaterestTemplate){this.restTemplate=restTemplate;}@GetMapping("/path1")publicResponseEntitypath1(){logger.info("Request at {} for request /path1 ",applicationName);Stringresponse=restTemplate.getForObject("http://localhost:8090/service/path2",String.class);returnResponseEntity.ok("response from /path1 + "+response);}@GetMapping("/path2")publicResponseEntitypath2(){logger.info("Request at {} at /path2",applicationName);returnResponseEntity.ok("response from /path2 ");}
Here I have created two paths, Path1 calling Path2 at a fixed port 8090. The idea here is to run two separate instances of the same application.
Now to allow sleuth to inject headers into the outgoing request, we need the RestTemplate to be injected as a bean rather than initializing it directly. This will allow sleuth to add an interceptor to the RestTemplate to inject a header with the trace id and span id into the outgoing request.
Now, let’s start the two instances. To do that, first, build the application with mvn clean verify and then run the following command to start “Service 1”
Once the application starts, call “Service 1” at /path1 as follows
curl -i http://localhost:8080/service/path1
Now let’s look at the logs of “Service 1”.
INFO [Service-1,222f3b00a283c75c,222f3b00a283c75c] 41114 ---[nio-8080-exec-1] c.a.p.distributedservice.Controller : Incoming request at Service-1 for request /path1
The log contains square brackets with three parts [ Service name, Trace Id, Span Id ]. For the first incoming request, since there is no incoming trace id, the span id is the same as the trace id.
Looking at the logs of “Service 2”, we see that we have a new span id for this request.
INFO [Service-2,222f3b00a283c75c,13194db963293a22] 41052 ---[nio-8090-exec-1] c.a.p.distributedservice.Controller : Incoming request at Service-2 at /path2
I intercepted the request being sent out of “Service 1” to “Service 2” and found the following headers already present in the outgoing request.
Here we see, the span for the next operation (call to “Service 2”) is already injected in the headers. These were injected by “Service 1” when the client was sending out the request. This means the span for the next call to “Service 2” is already started from the client of “Service 1”. In the headers shown above, The span id of “Service 1” is now the parent span id for the next span.
Now to make things easier to understand, we can visually see the traces using an interceptor tool called Zipkin.
Visualizing Traces with Zipkin
To integrate Zipkin with the application, we would need to add a Zipkin client dependency to the application.
We can now start the server using docker-compose up command. You can then access the UI at http://localhost:9411/
Since we are using the default port, we don’t need to specify any properties, But if you plan to have a different port, you would need to add the following property.
spring:zipkin:baseUrl:http://localhost:9411
With this done, let’s start both the applications using the same commands from above.
On placing a request to “Service 1” at the path /path1 we get the following traces.
Here it shows the spans for the two services. We can dig deeper by looking at the spans.
The span for “Service 1” is a normal span covering from when it received the request to it returning a response.
The interesting one is the second span.
In this, there are 4 points in the span.
The first point refers to when the client from “Service 1” started the request
The second point is when “Service 2” started processing the request.
The third point is when the client on “Server 1” finished receiving the response.
And finally, the last point when “Server 2” finished.
Conclusion
So with this, we have learned how we can integrate distributed tracing with spring cloud sleuth and also visualized the traces using Zipkin.
We value all of these things, and strive to balance or combine them for each situation.
Thoughtfulness and prescription.
Thoughtfulness means considering context, and taking action only after one has attempted to understand the situation. Prescription means following predefined steps, as in a framework, unchanged and not tailored to the situation, without necessarily understanding or being thoughtful about those steps or what they are for.
Outcomes and outputs.
Outcomes mean the direct and indirect end results that occur after one has taken action. Outputs refer to what is directly produced by an action: for example, working software is the output of a programming task. Outcomes require outputs, and both matter; but outcomes are what matter most.
Individuals and teams.
Individuals and their differences are important, and should never be forgotten: people are not the team that they belong to. Teams are important, and team spirit is important, and making agreements and compromises for the benefit of one’s team is important. But team interests and individual interests should be in balance: one is not more important than the other in an absolute sense.
Business understanding and technical understanding.
Technology personnel need to take an interest in business issues, and business personnel need to take an interest in technology issues. Neither should say, “I don’t need to know that.” Today, a holistic understanding of technology and business is necessary.
Individual empowerment and good leadership.
Individuals need to have agency: they need to be allowed to decide how to perform their own work, and they need to be given the opportunity to innovate and express new ideas and take chances to try those ideas. By so doing, they exercise personal leadership. Leaders of others need to empower those they lead, but they also need to assess how much freedom those can handle, and position them for growth.
Adaptability and planning.
Adaptability means expecting that plans need to change, and being prepared to revise plans. Planning is important because plans set direction for action, and they represent thought about what the best direction is.
We feel that these values are a better foundation for true agility.
We are Agile 2! A second iteration of Agile that understands and seeks to address today’s challenges….
Don’t be extreme, unless the situation is extreme.
Always think holistically – in terms of the whole system.
On Leadership:
Someone usually needs to coordinate things, and be the organizer.
On any team, one wants a “missionary, not mercenary” – someone who values the organization’s success first and foremost. A leader is part of a leadership team, and they need to see their own team(s) as the enablers of success, not as mere tools; such a leader is someone who delegates and empowers, but keeps a watchful eye; someone who encourages their team to develop and improve and expand their abilities, and become more independent over time.
There are many forms of leadership: team focused, advocate focused, technically focused, and maybe others; as well as individual leadership. (See our Leadership Taxonomy)
The organization needs to explicitly focus on encouraging benign and effective forms of leadership, and take steps to avoid giving the wrong people authority – avoiding people who “seem like leaders”, and instead selecting (actively or passively) those who are the “missionaries” and the helpers.
Leadership is needed at every level of an organization, and the same principles apply.
Leaders of tech-focused organizations not only need to understand outcomes, but they also need to understand how the work is done, because the “how” is often strategic.
On products:
Product design is an essential element, apart from product implementation; yet the two are intertwined.
Direct feedback from customers and stakeholders is the only way to measure success.
Product implementation teams must be partners with business stakeholders – not mere order takers.
On data:
Data is strategic, and it must not be treated as an afterthought.
On collaboration:
Collaboration is essential, but so is deep thought. People often need quiet and isolation in order to think deeply.
People work, communicate, and collaborate differently. These also vary by culture. Do not impose a one-size-fits-all approach. Some people need to write their ideas down before discussing. Others need to jump right to discussion. Be sensitive to different styles and personalities.
Team autonomy is an essential aspiration; but for a complex endeavor, full autonomy is seldom fully realizable.
Some people want to be experts. Some people want to be generalists. Some are inbetween. All are valuable.
Both teams and individuals matter. Don’t over-emphasize one over the other.
A team should collectively decide how to approach its work; but then individuals perform the work and interact as they need to.
On transformation and initiatives:
They are mostly a learning journey – not a process change.
On frameworks and methodologies:
Never use them as defined: treat them as a source of ideas – not an Agile-by-numbers process.